Sokoban
Sokoban: Machine Learning Puzzle Generation
This document describes the computational methodology underlying puzzle generation. 20 AI generated puzzles are provided as an example of the model's abilities. These puzzles are ordered from least to most difficult according to the model's evaluation.
1. Introduction
Puzzle design traditionally relies on iterative human refinement — a process that is time-consuming, difficult to scale, and subject to inconsistent difficulty calibration. This work presents an automated approach to puzzle generation using learned models that can produce infinite sequences of solvable puzzles with reproducible difficulty ratings.
The core challenge addressed is twofold: (1) generating puzzles that are guaranteed to be solvable, and (2) assigning difficulty scores that correlate with human solve times in a consistent manner.
2. Methodology
2.1 State Space Exploration
Rather than constructing puzzles forward from an initial configuration, the system adopts a reverse exploration strategy. Beginning from a randomly generated solved state — wherein all blocks occupy their designated goal positions — the system performs a breadth-first search (BFS) over the space of reverse actions.
Each reverse action corresponds to the mathematical inverse of a valid forward move. For Sokoban, this involves identifying states reachable by potentially "un-pushing" blocks from their goal positions. The BFS terminates when all reachable states have been enumerated, yielding a comprehensive set of solvable configurations.
This approach guarantees solvability by construction: every state in the explored tree can reach the solved state by definition. Each reverse action has a corresponding forward action.
2.2 Optimal Action Labeling
The reverse exploration produces states paired with their reverse-path actions. However, the shortest reverse path does not necessarily correspond to the shortest forward path. To obtain accurate training labels, the system performs a second BFS from the furthest discovered states from the solution — this time in the forward direction — to compute the optimal forward action (i.e., each action on the shortest path to solution).
This two-phase labeling process ensures that each training example contains the true optimal action, not merely a valid one.
2.3 Dataset Scale
The training corpus is generated from thousands of independently seeded solved states, each yielding dozens of reachable configurations. In aggregate, the dataset comprises approximately 2 million labeled state-action pairs, stored in a compressed HDF5 format for efficient batch loading during training.
2.4 Model Architecture
Two independent models are trained on the labeled dataset:
Forward Solver — A convolutional neural network that learns to predict the optimal action from
any given puzzle state. The architecture employs a series of residual blocks with squeeze-and-excitation attention,
processing a one-hot encoded grid representation. The model outputs a probability distribution over the forward
action space. This model can determine the optimal action to take for any solvable state to ~90% accuracy. Analysis of the model shows extraordinary accuracy when predicting actions within 5 steps of the solution. Below is a plot of the forward model average confidence from 1 to 90 steps away from a solution state.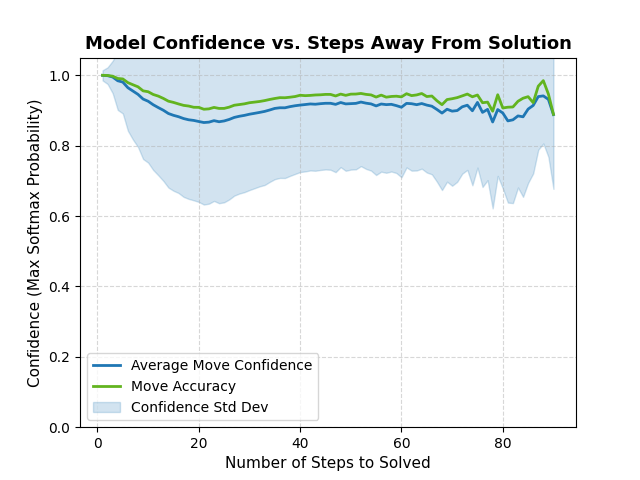
Reverse Scrambler — Trained on the same dataset with action labels inverted (i.e.,
predicting the reverse action that increases distance from the solution). The original intent was to use this model for
scrambling — generating starting states by iteratively applying the model's highest-confidence reverse
actions. The accuracy of this model was train to ~85%. Below is a plot of the forward model average confidence from 1 to 90 steps away from a solution state.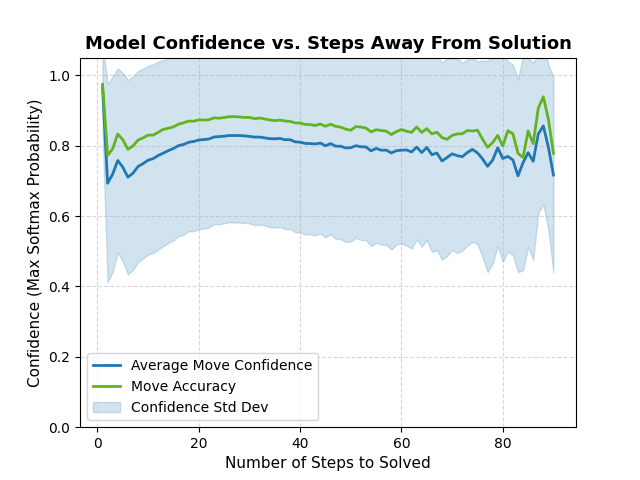
2.5 Empirical Findings: Reverse Model Performance
Initial experiments evaluated whether the reverse model could serve as an efficient scrambler, replacing the need for exhaustive BFS backtracking. The hypothesis was that a learned model could approximate the space of "hard" starting states without exploring every intermediate configuration.
Results indicated that the reverse model, despite achieving decent training accuracy, failed to consistently produce states at maximal distance from the solution. The learned policy tended to converge to local maxima rather than discovering the true furthest-reachable states.
Consequently, the current pipeline employs BFS backtracking to identify optimal starting configurations — the same algorithm used for labeling, but applied at generation time to select the highest-difficulty state from the explored tree. This approach is computationally more expensive than model-based scrambling but guarantees optimal results.
The reverse model remains trained for potential future use, particularly in hybrid approaches that combine learned policies with explicit search.
3. Difficulty Quantification
Difficulty is computed using the forward solver's output distribution. For a given puzzle state s, let p(a|s) denote the model's predicted probability for action a. The per-step difficulty contribution is:
D(s) = -Σ_a p(a|s) · log p(a|s)
This is the Shannon entropy of the action distribution. High entropy indicates that the model assigns similar probability to multiple actions — i.e., the optimal move is ambiguous. Low entropy indicates a clear preferred action.
The total difficulty of a puzzle is the sum of per-step entropies along the optimal solution path:
Difficulty = Σ_s∈path D(s)
This metric correlates with solution path length and branching factor, providing a principled alternative to human playtesting. It should be noted that without explicit human evaluation, this is only an approximation of true difficulty.
4. Results and Discussion
The pipeline produces puzzles with the following properties:
- Guaranteed solvability — every generated puzzle can be solved
- Reproducible difficulty — the same score always represents equivalent complexity
- Scalable generation — millions of puzzles can be generated from a single trained model
- Novel configurations — the BFS exploration discovers patterns that differ from human-designed levels
The primary limitation of the current approach is variation: puzzles are generated by exploring backward from randomly generated solutions, then selecting a starting state. This constrains the distribution of achievable difficulties to those present in the explored state space and, as such, are not guaranteed to be interesting or even difficult.
5. Future Work
5.1 Targeted Difficulty Generation
The current method generates puzzles first, then filters by difficulty. A more efficient approach would train a model to directly produce initial states of a specified difficulty level; however guaranteeing solvability becomes a computational bottleneck and so a more practical approach is to train the model to generate solved puzzle states, then apply reverse actions in a BFS search similar to how the initial training set was produced. The states 'furthest' from the solution are considered approximately optimally scrambled and can be evaluated. This would require:
- Training a generative model conditioned on difficulty embeddings
- Using the forward model as a differentiable loss function during generation
- Applying backpropagation through the solver to optimize initial state parameters
5.2 Style and Curriculum Learning
Beyond difficulty, future work could explore encoding puzzle "style" — characteristics that affect player experience without changing difficulty. Curriculum learning could progressively introduce mechanics, training on easier puzzle types before advancing to complex configurations.
5.3 Human-in-the-Loop Design
Integrating designer constraints into the generation process would enable hybrid workflows: specify required elements (e.g., "include a T-shaped room"), then let the system generate valid puzzles satisfying those constraints.
Implemented in PyTorch. Dataset stored in HDF5 format. Training conducted on CUDA-enabled hardware with TensorBoard monitoring.

Leave a comment
Log in with itch.io to leave a comment.